Enhancing Bumblebee X Stereo Depth Estimation with Deep Learning Techniques
Overview
Stereo depth estimation is essential for robotics (bin picking, pick-and-place, AGV/AMR navigation), augmented and virtual reality, and industrial inspection. The Teledyne Bumblebee X stereo camera delivers high-accuracy disparity maps at up to 17.2 FPS at 2048×1536 resolution, making it well suited for embedded and real-time applications.
The Bumblebee X camera utilizes a Semi-Global Block Matching (SGBM) algorithm optimized for speed and accuracy. While SGBM performs well on textured surfaces, it can struggle with textureless or reflective regions, producing gaps and incomplete disparity coverage. These limitations affect applications such as autonomous navigation, 3D reconstruction, and industrial inspection.
This application note evaluates two deep learning approaches designed to improve disparity accuracy and completeness:
- Disparity Refinement: Methods such as LingBot-Depth take the on-board SGBM disparity and the left RGB image as inputs and produce a refined, more complete depth map.
- End-to-End Deep Learning Stereo: Methods such as Selective-Stereo and FoundationStereo estimate disparity directly from stereo image pairs, typically at higher computational cost.
The Deep Learning examples in this application note are available on GitHub.
Stereo Depth Estimation: Challenges and Limitations
Classical stereo algorithms like SGBM provide fast, efficient disparity estimation ideal for embedded real-time applications. They handle well-textured surfaces effectively without requiring training data or GPU resources. However, they struggle with low-texture or reflective surfaces, producing disparity holes and streaking artifacts.
Figures 1 and 2 show a rectified left image and the corresponding on-board disparity map from a typical warehouse scene. This environment presents several challenges for SGBM: long parallel shelving with repetitive patterns, a glossy epoxy floor, and strong specular reflections from overhead lighting. With MinDisparity set to 0 and a 256-level disparity range, objects closer than approximately 1.6 m fall outside the measurable depth window, leaving blank regions at the image borders. To capture closer objects, increase MinDisparity (Scan3D Coordinate Offset) or use quarter-resolution mode to extend the effective range, though with reduced spatial detail. Additional gaps appear on shelf faces where repetitive texture confuses the matcher, and floor reflections introduce false correspondences.
 |
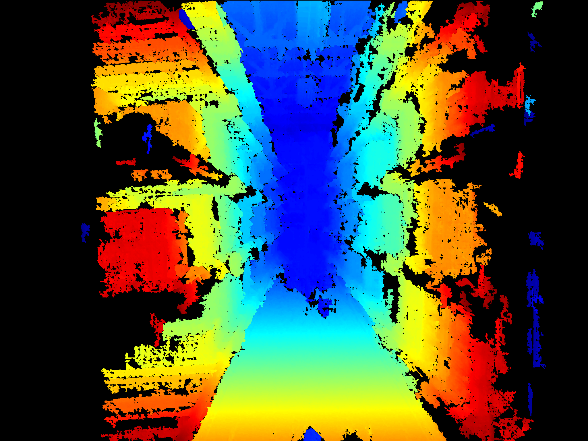 |
| Figure 1: Rectified Left Image | Figure 2: Disparity computed on-board with SGBM stereo matching |
The resulting disparity map shows holes and fragmented estimates on shelf faces due to repetitive structure, false correspondences from floor and lighting reflections, and edge bleeding at depth boundaries. Overall, the map is sparse and noisy in key regions, limiting downstream depth perception.
To overcome these limitations, deep learning stereo matching algorithms offer two approaches:
End-to-end deep learning methods (e.g., Selective-Stereo and FoundationStereo) achieve dense, accurate disparity predictions even with occlusions and reflective surfaces by leveraging learned semantic and contextual information. However, their computational demands limit real-time applicability without significant GPU acceleration.
Disparity refinement approaches (e.g., LingBot-Depth) bridge classical and end-to-end methods by enhancing SGBM output with improved completeness and accuracy, while maintaining a lower computational footprint.
The following sections detail each approach and compare accuracy, runtime, and coverage.
Deep Learning-based Disparity Refinement (LingBot-Depth)
Method Description
LingBot-Depth enhances disparity maps produced by classical methods such as SGBM. It employs a Vision Transformer (ViT-Large) backbone conditioned on the initial depth map to:
- Fills disparity gaps based on learned spatial, contextual, and structural priors
- Sharpens edges through transformer-based attention mechanisms
- Reduces common stereo matching artifacts like streaking and false matches
How It Works
The refinement pipeline processes two inputs:
- The left RGB image from the stereo camera
- The corresponding depth map, derived from the raw disparity map generated on-board by the Bumblebee X camera and using known camera intrinsics
The on-board disparity is first converted to a metric depth map using the camera’s focal length and baseline. These inputs, along with normalized camera intrinsics, are passed to the LingBot model, which produces a refined depth estimate. The refined depth can be converted back to disparity for comparison and downstream use.
Performance
LingBot-Depth achieves approximately 5.9 FPS on an NVIDIA RTX 5070 Ti GPU at full resolution (2048×1536), making it suitable for near-real-time enhancement.

Figure 3: Disparity refined by LingBot-Depth
As shown in Figure 3, applying LingBot-Depth to the warehouse scene fills most holes, corrects floor mismatches, and produces a substantially more complete depth map. Areas where SGBM had no initial data (for example, beyond the disparity range at image borders) may retain some residual gaps, though overall coverage is dramatically improved.
Deep Learning-based Disparity Estimation (Selective-Stereo)
Method Description
Selective-Stereo computes disparity maps directly from stereo image pairs without relying on traditional matching algorithms. Built on the IGEV-Stereo architecture with iterative GRU refinement, it employs adaptive frequency selection to optimize processing for different image regions.
Network Architecture
This method dynamically adjusts computational focus based on image frequency characteristics:
- High-frequency branch enhances edges and fine details
- Low-frequency branch maintains smooth regions and avoids overfitting
Performance
Selective-Stereo is computationally demanding, achieving approximately 0.67 FPS on an NVIDIA RTX 5070 Ti at full resolution (2048×1536).

Figure 4: Disparity estimated from Selective-Stereo
As shown in Figure 4, the end-to-end approach delivers wide disparity coverage and preserves fine structural detail while avoiding speckle artifacts from reflections.
Deep Learning-based Disparity Estimation (FoundationStereo)
Method Description
FoundationStereo is a foundation model for stereo depth estimation developed by NVIDIA. Unlike task-specific stereo networks, it generalizes zero-shot to arbitrary scenes without fine-tuning, combining a DINOv2 vision transformer backbone with correlation-based cost volumes and iterative GRU refinement.
Network Architecture
FoundationStereo employs a two-stage hierarchical inference strategy for high-resolution images:
- A coarse pass at reduced resolution to establish an initial disparity estimate
- A full-resolution refinement pass that uses the coarse estimate as initialization
This approach allows the model to handle large images while maintaining fine detail.
Performance
FoundationStereo (fast variant with hierarchical inference) runs at approximately 0.21 FPS on an NVIDIA RTX 5070 Ti at full resolution (2048×1536). While the slowest method tested, it delivers the highest accuracy across both textured and textureless scenes.

Figure 5: Disparity estimated from FoundationStereo
As shown in Figure 5, FoundationStereo produces complete, dense disparity maps with excellent accuracy, handling textureless regions, reflections, and repetitive patterns with consistent robustness across all test conditions.
Key Takeaways
On-board SGBM remains the best choice for high-speed embedded depth estimation, delivering accurate results on well-textured surfaces at real-time frame rates. Performance degrades significantly in textureless, reflective, or repetitive environments. LingBot-Depth refinement provides a practical middle ground, substantially improving coverage while maintaining near-real-time performance. End-to-end methods (Selective-Stereo, FoundationStereo) deliver the most complete and accurate disparity maps but require greater computational resources. The optimal approach depends on the application: SGBM for maximum speed, LingBot-Depth for balanced performance, and end-to-end stereo when accuracy matters more than latency.
Additional Considerations
Surfaces closer than the minimum measurable depth (outside the 0–256 disparity window) may not be handled correctly by deep learning stereo models. For example, the storage bin in the lower-right corner is very close to the camera and should appear in the extreme red disparity range, yet some networks assign a smaller disparity value, placing it farther than its actual position.
Some deep learning models allow tuning the minimum disparity directly. For models that do not, shift the right image left by the desired minimum-disparity offset in pixels, then add that value back to each output disparity.
Similarly, models that limit disparity range may require resizing the input images to maintain the same measurable depth range, at the cost of reduced depth precision.
Many models require scene-specific fine-tuning, whereas advanced foundation stereo networks (for example, FoundationStereo) generalize zero-shot. SGBM and SGBM-based hybrid approaches deliver reliable out-of-the-box performance without tuning.
Comparative Experimental Analysis
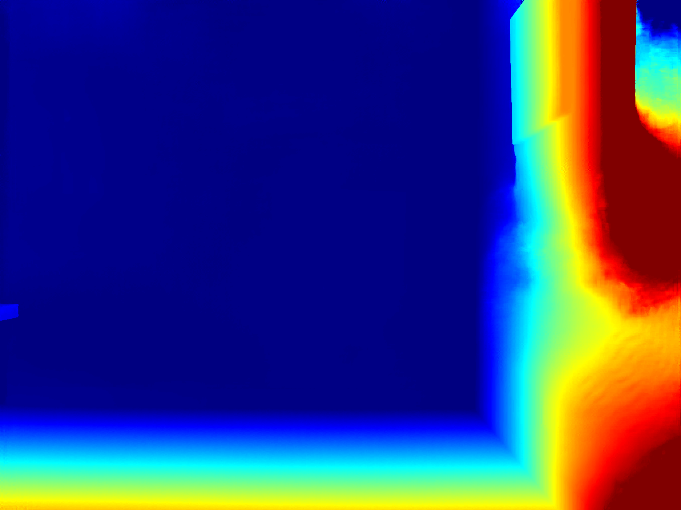
A benchmark was conducted using a flat target at a known distance of approximately 3.028 m. The camera operated at full resolution (2048×1536), and a region of interest (ROI) was defined within the target surface. Coverage and accuracy were evaluated under two conditions: textured and textureless (smooth) surfaces.

Figure 6: Scene for accuracy and coverage estimation
 |
 |
 |
 |
| Figure 7: On-board disparity | Figure 8: LingBot Depth refined disparity | Figure 9: Selective-Stereo disparity | Figure 10: FoundationStereo disparity |
Results - Textured Region
| Method | Category | Coverage % |
Median Depth (mm) | Median Error (mm) |
Median Error (%) |
Frame Rate (FPS) |
| SGBM (on-board) | Classical Stereo | 100.0 | 3036.84 | +8.84 | +0.29 | 17.3 |
| SGBM + LingBot-Depth | Classical + refinement | 100.0 | 3017.21 | -10.79 | -0.36 | 5.9 |
| Selective-Stereo | DL stereo | 100.0 | 3037.56 | +9.56 | +0.32 | 0.67 |
| FoundationStereo | Foundation DL stereo | 100.0 | 3033.97 | +5.97 | +0.20 | 0.21 |
Results - Textureless Region
| Method | Category | Coverage % |
Median Depth (mm) | Median Error (mm) |
Median Error (%) |
Frame Rate (FPS) |
| SGBM (on-board) | Classical Stereo | 10.6 | 4418.31 | +1390.31 | +45.92 | 17.3 |
| SGBM + LingBot-Depth | Classical + refinement | 100.0 | 3316.59 | +288.59 | +9.53 | 5.9 |
| Selective-Stereo | DL stereo | 100.0 | 3050.55 | +22.55 | +0.74 | 0.67 |
| FoundationStereo | Foundation DL stereo | 100.0 | 3037.20 | +9.20 | +0.30 | 0.21 |
Notes:
- All deep learning timings measured on an NVIDIA RTX 5070 Ti (16 GB) at full resolution 2048×1536. SGBM frame rate is the on-board processing rate at full resolution 2048×1536.
- Frame rates can be significantly improved by using higher-end GPUs, reducing resolution, or converting models to optimized runtime formats such as ONNX or TensorRT.
Observations
Textured surfaces (easy case): All stereo methods achieve sub-0.4% error. When stereo matching has sufficient texture to work with, even classical SGBM is highly accurate on valid pixels. FoundationStereo leads at 0.20%, followed closely by Selective-Stereo at 0.32%.
Textureless surfaces (hard case): This is where the methods diverge dramatically:
- On-board SGBM drops to just 10.6% coverage with 46% error on the remaining pixels, a classic failure mode for block-matching algorithms on smooth surfaces.
- LingBot-Depth refinement recovers full coverage but retains +9.5% error, inheriting inaccuracy from the degraded SGBM input.
- Selective-Stereo and FoundationStereo maintain 100% coverage with sub-1% error, demonstrating that learned stereo networks can handle textureless regions that defeat classical matchers.
Speed vs. accuracy trade-off: On-board SGBM is by far the fastest (17.2 FPS). LingBot-Depth refinement adds substantial value at a modest speed cost (~6 FPS). The end-to-end DL stereo methods deliver the highest accuracy but at significantly lower frame rates (< 1 FPS).
Coverage is also influenced by post-processing settings. Lowering the uniqueness ratio increases coverage; raising it suppresses noisy points at the cost of completeness. Similarly, adjusting confidence thresholds in deep learning networks balances accuracy against completeness. This study used default Bumblebee X camera settings throughout.
Practical Application Guidelines
Recommended approaches by application scenario:
- High-Speed Real-Time (≥17 FPS): Use Bumblebee X’s on-board SGBM, optionally with a pattern projector for improved completeness in textureless scenes.
- Balanced Coverage and Latency (~6 FPS): Add LingBot-Depth refinement as a post-processing step on SGBM output, recovering full coverage with modest hardware requirements.
- Highest Accuracy and Completeness (<1 FPS): Use FoundationStereo or Selective-Stereo when low frame rate is acceptable. FoundationStereo offers slightly better accuracy on textureless surfaces; Selective-Stereo is approximately 3× faster.
Conclusion
Deep learning methods significantly enhance the Bumblebee X camera depth maps, each with distinct strengths. LingBot-Depth refinement delivers near-real-time coverage improvements at modest hardware cost, recovering full disparity maps from sparse SGBM output. End-to-end stereo networks like Selective-Stereo and FoundationStereo provide the highest accuracy and completeness, particularly on textureless surfaces, where speed is secondary. The optimal choice depends on the application’s requirements for speed, accuracy, and hardware availability.